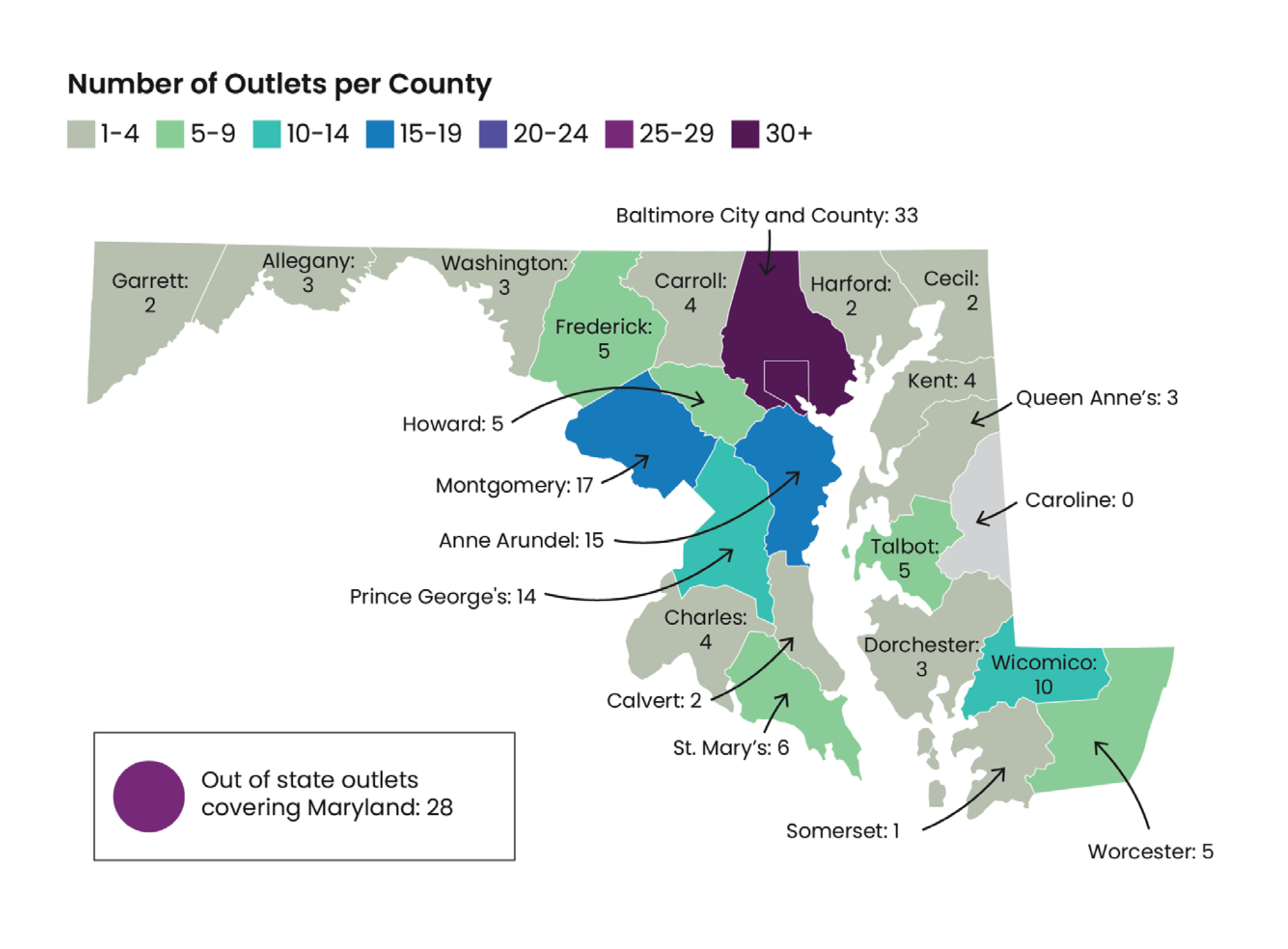
Social Science One, the non-profit commission launched in 2018 to establish concrete partnerships between academics and data-rich institutions like Facebook, now has 32 million individual links extracted from Mark Zuckerberg’s social media network upon which to conduct research.
After an unexpected delay of almost a year, something that created an upset with the project’s founders, the coalition of researchers finally received from Facebook what is considered to be “one of the largest sets of links ever created for academic research.”
At least that’s what Solomon Messing, former director at Pew Researcher Center’s Data Lab and now manager of data science for Social Science One, told the IFCN.
Now, teams of researchers selected from around the globe will be able to use the dataset to identify trends, patterns and popular topics within the world of content on Facebook.
According to the platform, the dataset includes the number of times the URLs were shared publicly, the date they were first shared, the date they were first fact-checked, the country in which they were most shared, and a summary of the actual content contained in the URL.
It also includes data on user interaction, including the number of times a URL was flagged by a user as containing false news and the number of times a URL was shared without being actually clicked on.
Facebook said it selected these data points because they are widely thought to be indicators of misinformation. From now on, researchers can use them to understand the kind of topics that dominate on the platform or to create machine learning models based on these patterns.
To access the set of about 32 million URLs, academics must have their projects approved by the Social Science One commission. Proposals that are accepted may be awarded funding, data and other benefits. And all resulting papers can be published according to the researcher’s wishes, without any additional restrictions from Facebook or the commission.
“We’re continuing to make additional data available in a way that protects people’s privacy,” said Messing. “This data set will allow researchers to answer important questions about misinformation and the role of social media in society.”
Expectations are high.
A delay in data delivery
In April 2018, when Facebook announced it was partnering with academics to provide them with valuable data for misinformation research, it was anticipated that these datasets would take some time to prepare. But not this long.
In August, Buzzfeed News reported that Social Science One’s funders, including the Democracy Fund, the William and Flora Hewlett Foundation, the John S. and James L. Knight Foundation, the Charles Koch Foundation and Omidyar Network were threatening to pull out of the project because of the delay.
According to the report, they gave Facebook a deadline of Sept. 30 to share the datasets it had promised or the project would come to an end.
In January, however, Social Science One had notified in a blog post that Facebook would need more time to release a URL dataset citing privacy concerns.
“Facebook not only must comply with the new General Data Protection Regulation of the European Union, as well as similar privacy laws in jurisdictions around the world, but it must also comply with Facebook’s consent decree with the U.S. Federal Trade Commission,” the blog post read. “Because of the unprecedented nature of our project, Facebook is moving slowly and cautiously to ensure that our project complies with all relevant legal guidelines.”
The dataset was released in mid-September, just ahead of the deadline that Buzzfeed reported.
How were privacy concerns managed?
According to Facebook, differential privacy was added to the URLs that entered the dataset. This means that any individual’s contribution to the data has been masked.
Facebook said it characterized differential privacy as additional “statistical noise” that provides people an extra layer of protection and keeps them safe from cyber-attacks.
What research is made feasible by this dataset?
An earlier version of the URL dataset, which was made available to approved researchers via the social monitoring platform CrowdTangle, was already used in a study about coordinated inauthentic link-sharing behavior in the run-up to the 2019 European elections in Italy.
Now, researchers will be able to use the full dataset to better understand what kinds of content and topics are prevalent on Facebook. They’ll be able to identify patterns in what is shared over time, and could potentially build machine-learning models that spot misinformation.
Facebook said that researchers have long been aware of the need for a large and diverse dataset to train such a machine-learning model. This URL dataset is among the largest in existence, at 7 gigabytes containing approximately 32 million URLs and about 544 million cell values.
Academics might be able to identify how trending content is related to political events and product roll-outs at Facebook. Other potential topics of study include how polarization, politicians and news cycles play a role in the spread of misinformation on the platform.