Searching for data to back up your story? Just Google it, verify the accuracy of the source, and you’re done, right? Not quite. Accessing information to support our reporting is easier than ever, but very little information comes in a structured form that lends itself to easy analysis.
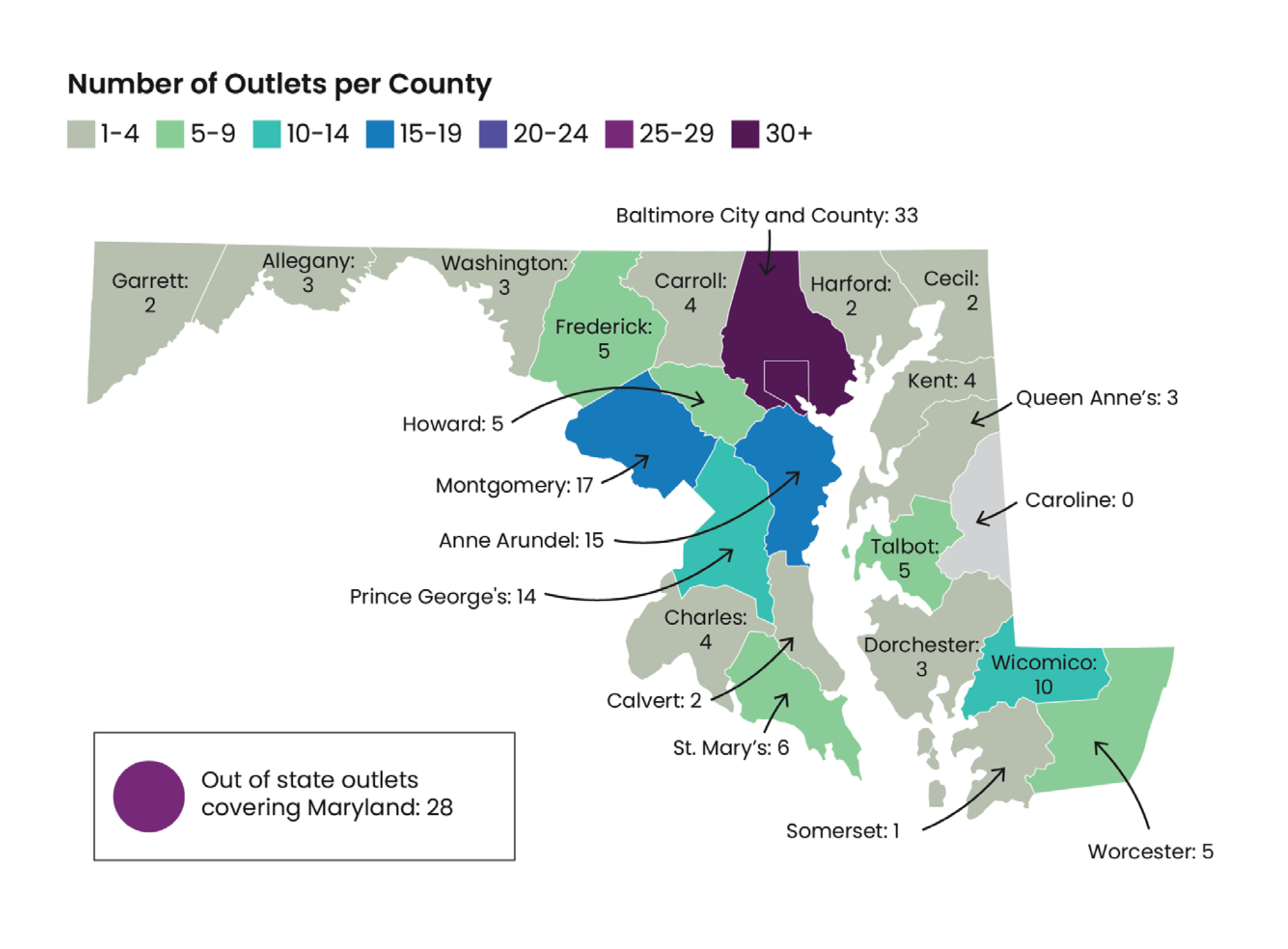
You may be fortunate enough to receive a spreadsheet from your local public health agency. But more often, you’re faced with lists or tables that aren’t so easily manipulated. It’s common for data to be presented in HTML tables — for instance, that’s how California’s Franchise Tax Board reports the top 250 taxpayers with state income tax delinquencies.
It’s not enough to copy those numbers into a story; what differentiates reporters from consumers is our ability to analyze data and spot trends. To make data easier to access, reorganize and sort, those figures must be pulled into a spreadsheet or database. The mechanism to do this is called Web scraping, and it’s been a part of computer science and information systems work for years.
It often takes a lot of time and effort to produce programs that extract the information, so this is a specialty. But what if there were a tool that didn’t require programming?
Enter OutWit Hub, a downloadable Firefox extension that allows you to point and click your way through different options to extract information from Web pages.
How to use OutWit Hub
When you fire it up, there will be a few simple options along the left sidebar. For instance, you can extract all the links on a given Web page (or set of pages), or all the images.
If you want to get more complex, head to the Automators>Scrapers section. You’ll see the source for the Web page. The tagged attributes in the source provide markers for certain types of elements that you may want to pull out.
Look through this code for the pattern common to the information you want to get out of the website. A certain piece of text or type of characters will usually be apparent. Once you find the pattern, put the appropriate info in the “Marker before” and “Marker after” columns. Then hit “Execute” and go to town.
An example: If you want to take out all the items in a bulleted list, use <li> as your before marker and </li> as your after marker. Or follow the same format with <td> and </td> to get items out of an HTML table. You can use multiple scrapers in OutWit Hub to pull out multiple columns of content.
There’s some solid help documentation to extend your ability to use OutWit Hub, with a variety of different tutorials.
If you want to extract more complicated information, you can. For instance, you can also pull out information from a series of similarly-formatted pages. The best way to do this is with the Format column in the scraper section to add a “regular expression,” a programmatic way to designate patterns. OutWit Hub has a tutorial on this, too.
OutWit Hub isn’t the only non-programming scraping option. If you want to get information out of Wikipedia and into a Google spreadsheet, for instance, you can.
But even when pushed to the max, OutWit Hub has its limitations. The simple truth is that using a programming language allows for more flexibility than any application that relies on pointing and clicking.
When you hit OutWit’s scraping limitations, and you’re interested in taking that next step, I recommend Dan Nguyen’s four-post tutorial on Web scraping, which also serves as an introduction to Ruby. Or use programmer Will Larson’s tutorial, which teaches you both about the ethics of scraping (Do you have the right to take that data? Are you putting undue stress on your source’s website?) while introducing the use of the Beautiful Soup library in Python.



Comments