
You may already know about a website that lets you peek into the past. This week, we dig into tools on that site that make it easy to save what you find.
Hare: Hey, Ren, what are we talking about this week?
LaForme: Let’s talk about history. Most people are aware of the Internet Archive Wayback Machine. For those who aren’t aware of it, the Wayback Machine is a search service that can show you old versions of a website. This is great because, as we know, sometimes people try to change things on their websites — which are essentially their online personas — and pretend like it didn’t happen.
I’ve been using it for years and years, but this week I spoke to Gary Price, a researcher, librarian and founder of Infodocket.com, who clued me in on some Wayback Machine features I never knew about.
Hare: Oh excellent. Librarians are always full of good surprises.
LaForme: I wish newsrooms still kept a bunch of them around. That’s a huge loss for us.
Anyway, the first thing I learned about the Wayback Machine is that you can actually set it to capture a page manually. There’s a little search bar on the bottom right side of the Wayback Machine home page (notably, it’s not on the archive.org homepage) that lets you enter a URL and grab any page that’s currently online.
It also gives you the option to download a PDF of that page as it’s captured. That’s something you can already do from most browsers, but it’s a great two-step process of capturing a site that you think needs to be archived for some purpose.
Hare: I love shortcuts. How do you see journalists using this?
LaForme: As a journalist, I’m particularly interested in holding those in power accountable. So I’m going to suggest grabbing archives of government websites, websites for big corporations, large donors to politicians and lobbyists and the like, and other organizations with power.
But you can literally use it for anything. I mean, if you’re particularly proud of how your news organization’s front page is looking on a given day, grab an archive. People will see it when they go back to look at that URL in the Internet Archive.
Hare: We’ve talked before about other ways to monitor changes on websites, but I want to spend a little more time on the second function you mentioned: archiving your own work. I wrote about this a few years ago, told myself I needed to go save some stories from when I lived in St. Louis, and now a lot of them are gone. When your work appears on the internet, it’s really easy for it to just disappear.
I spoke to someone at RJI who’s working on this, and his advice was – make a PDF of your stories. This seems like a very easy way to set that up.
LaForme: Absolutely. My online writing only goes back a little over a decade, but I’d say that half of it has already been swallowed by the shifting sands of the internet. I’m missing a ton of articles from high school and college, maybe for the better.
My advice for that, since the Internet Archive focuses more on homepages, would be to use your browser to grab PDFs of your articles. On a Mac, you just hit the print button under “File” on any browser and use the PDF functionality within it. On a PC, I think it’s roughly similar, but it depends on the browser. It should take you just a few seconds for each article. I’d recommend keeping them in a folder that syncs to Google Drive or Dropbox just to make sure they’re safe.
Hare: That’s embarrassingly simple. What else did you learn about?
LaForme: Oh, this one makes it even easier. You know I love shortcuts and making workflows easier, so the second thing I learned is that there’s a bookmarklet that lets you archive a page without going to the Wayback Machine website. Since it’s a bookmarklet, it should work on all browsers. It’s a handy little tool.
Hare: Yes, the less steps the better. This is why I’m horrible at cooking. (Gonna keep telling myself that.) Have you seen any cool ways journalists have used WBM?
LaForme: I think it’s most useful as a research tool, which is how most journalists are using it. So, if you’re using it the way I described, you’re basically giving the future version of you a high five and making it easier to conduct research in the future. I think I’m going to start caching the websites of major digital tool makers just so I can have something to look back on.
Hare: Agreed, it’s a great way to peek into the past and see what the places and people we cover were like. Is there anything you’d change or add if you could?
LaForme: I do wish it went deeper on websites, but can you imagine the storage that would take? It would be ridiculous. Also, it doesn’t have the ability to archive sites with anti-crawling code.
One limitation I found the other day, when I accidentally deleted a friend’s entire front page layout, is that it doesn’t capture the CSS and images for every site. I had to use another site, called Cachedview, to grab all of that stuff to fix his site. Just another reminder that it’s important to employ a whole toolbox from time to time.
Hare: Want to see something cool?
LaForme: Obviously!
Hare:
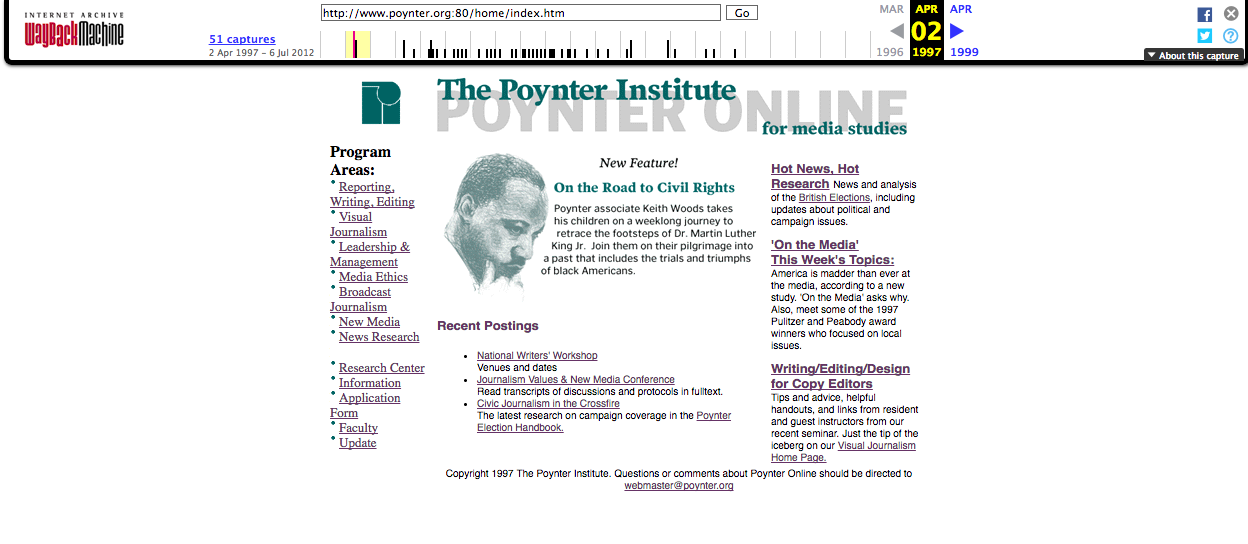
Poynter.org circa 1997.
“America is madder than ever at the media, according to a new study.”
Guess it’s been a rough two decades…
LaForme: Wow! Look at that page. It’s… something. I guess some things change and others don’t change that much at all.
Editor’s note: This is the latest in a series of articles that highlight digital tools for journalists. You can read the others here. Got a tool we should talk about? Let Ren know!
Learn more about journalism tools with Try This! — Tools for Journalism. Try This! is powered by Google News Lab. It is also supported by the American Press Institute and the John S. and James L. Knight Foundation.




